When data prep turns into p-hacking
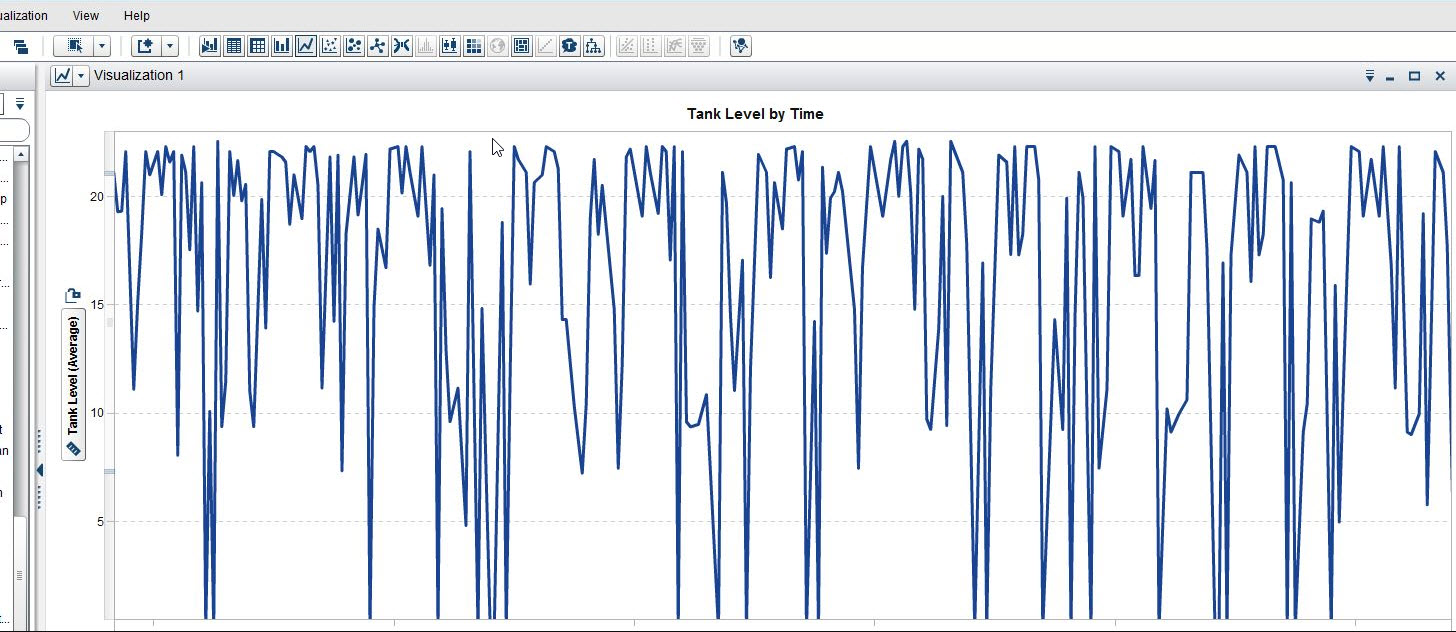
One might assume that data generated by sensors and event recorders would be clean because after all, these are precise instruments, right? Alas, the analytics of things suffers from the age-old challenge of data quality. This screenshot from SAS Visual Analytics show that for several minutes, the tank level measurement mysteriously drops to zero quite frequently.

Recently we encountered quite a few of these anomalous measurements on a project. As part of our data quality and preparation routines we set up a “bimodality detector” to isolate these patterns. But then what to do with that data? Options range from throwing it out, to employing various imputation and outlier remediation techniques, both simple and elaborate.
We found this is a slippery slope. We can run our entire process end-to-end, from data intake to model calibration, and see the end results of our remedies. When the stakeholders have a particular answer in mind it’s tempting to tune the remedies, running the process over and over again to approach that answer.
P-hacking is a type of data-dredging wherein one has an answer in mind, and, speaking in the traditional regression sense, one selects variables and a model specification to support the desired outcome. The ‘p’ refers to the p-value used in traditional statistical hypothesis testing.
But while we think of p-hacking as relating to the building of the model or algorithm, it turns out that outcomes sometimes can be influenced more by how the data coming in is transformed.
Machine learning techniques sometimes are perceived to be objective. But there is obvious subjectivity in the selection of the algorithm and its parameters. Taken together with this ability to intervene within the data preparation stage, there is even more subjectivity from end-to-end.
This is not to say it is wrong to have human domain knowledge inform the analytics process — in fact, the best analytics are steered in the right direction by a human modeler. But let’s dispense with the illusion that “data driven” decisions are free from human biases.